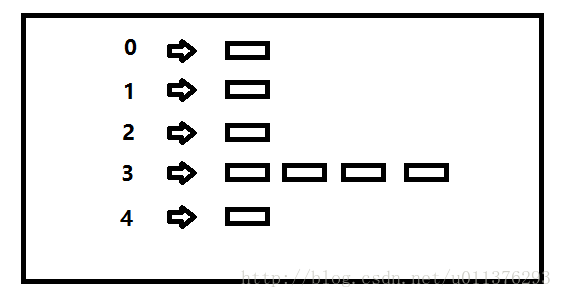
哈希表
哈希表 (Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过 把关键码值映射到表中一个位置 来访问记录,以加快查找的速度。这个映射函数叫做 散列函数 ,存放记录的数组叫做散列表。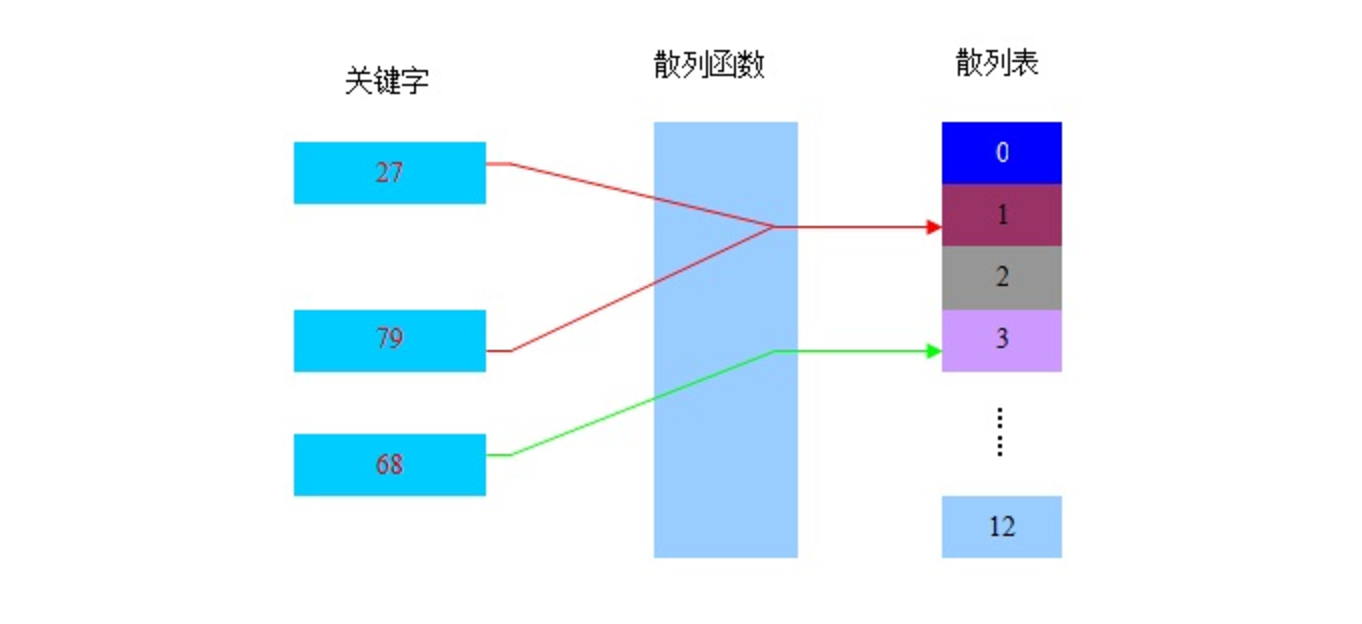
使用哈希查找有两个步骤:
- 使用哈希函数将被查找的键(关键码)转换为数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值的情况。所以哈希查找的第二个步骤就是处理冲突
- 有很多处理哈希碰撞冲突的方法,本文后面会介绍拉链法和线性探测法。
为什么使用哈希表
- 对于数组来说其优势是查找十分的方便快速,但是增添删减元素却不方便
- 对于链表来说增添删除元素方便,但是查找却不方便。
- 所哈希表可谓是结合了链表跟数组的优点,查找方便,增添删除元素也方便。
哈希函数
哈希查找第一步就是使用哈希函数将键映射成索引。这种映射函数就是哈希函数。如果我们有一个保存0-M数组,那么我们就需要一个能够将任意键转换为该数组范围内的索引(0~M-1)的哈希函数。哈希函数需要易于计算并且能够均匀分布所有键。比如举个简单的例子,使用手机号码后三位就比前三位作为key更好,因为前三位手机号码的重复率很高。再比如使用身份证号码出生年月位数要比使用前几位数要更好。
在实际中,我们的键并不都是数字,有可能是字符串,还有可能是几个值的组合等,所以我们需要实现自己的哈希函数。
正整数
获取正整数哈希值最常用的方法是使用除留余数法。即对于大小为素数M的数组,对于任意正整数k,计算k除以M的余数。M一般取素数。
字符串
霍纳算法:当key是字符串时,先计算字符串中各个字符的unicode码值,然后进行求和,每次求和要乘上一个质数,比如31. 最后求余数1
2
3
4
5
6
7
8
9
10
11
12function betterHash(key) {
const H = 37;
var total = 0;
for (var i = 0; i < key.length; i++) {
total += total * H + key.charCodeAt(i);
}
total = total % this.table.length;
if (total < 0) {
total += this.table.length - 1;
}
return parseInt(total, 10);
}
举个例子,比如要获取”call”的哈希值,字符串c对应的unicode为99,a对应的unicode为97,L对应的unicode为108,所以字符串”call”的哈希值为 3045982 % length = 99·313 + 97·312 + 108·311 + 108·310 = 108 + 31· (108 + 31 · (97 + 31 · (99))) % length
如果对每个字符去哈希值可能会比较耗时,所以可以通过间隔取N个字符来获取哈西值来节省时间,比如,可以 获取每8-9个字符来获取哈希值:
1 | function betterHash(key) { |
但是,对于某些情况,不同的字符串会产生相同的哈希值,这就是前面说到的哈希冲突(Hash Collisions),比如下面的四个字符串:
如果我们按照每8个字符取哈希的话,就会得到一样的哈希值。
构建一个散列表
我们使用一个类来表示散列表,该类包含计算散列值(关键码值)的方法、向散列中插入数据的方法、向散列中读取数据的方法、显示散列表中数据的分布的方法、以及其他一些可能会用到的方法。1
2
3
4
5
6
7
8function HashTable() {
this.table = new Array(137);
this.simpleHash = simpleHash;
this.betterHash = betterHash
this.showDistro = showDistro;
this.put = put;
this.get = get;
}
避免哈希冲突
拉链法
拉链法指实现散列表的底层数组中,每个数组元素又是一个新的数据结构,比如另一个数组,这样就能储存多个键了。使用这种技术,即使两个键散列后的值相同,依然被保存在同样的位置,只不过它们在第二个数组中的位置不一样罢了。
一般第二个数组被称为链。一般一个链中两个连续的单元格保存一个元素。第一个保存键值,第二个保存数据。